
Intel平台上的LLM聊天機器人
2024-07-11
在人工智慧的浪潮中,大型語言模型 (LLM) 如GPT-4已經成為了技術革新的前沿。 像這樣的大型語言模型,能夠處理複雜的語言任務和深度對話。
除大型語言模型外,同時也發展了許多比較小型的LLM,這些小型模型在保持了一定的對話能力和語言理解的同時,由於其輕量級的特性,使得它們能在資源受限環境中實現智能對話,非常適合在邊緣裝置或記憶體較小的平台上運行,且比起在雲端運作的大語言模型,提供了更顯著的隱私和安全性優勢。
例如,在醫療領域,地端運作可確保敏感的健康記錄不會被未經授權的第三方訪問。 同樣,在企業環境,地端運作可保持商業秘密和內部通訊的機密性。
藉由Intel OpenVINO,即可快速的建立並部署符合此特性的小型規模的LLM聊天機器人。
Intel OpenVINO Toolkits在大型語言模型上的幾個特點都可以發揮優勢。
• 大型語言模型使用深度學習算法和大量數據來學習語言的細微差別,產生連貫且相關的回應。
√ OpenVINO可以在Intel平台上能善用所有算力 (CPU/GPU/NPU/etc.) ,發揮深度學習推論最佳的效能。
• 大型語言模型利用Transformer做為核心架構,可識別文本中不同語句間的關係並給予不同的權重,是自然語言處理的重要核心。
√ OpenVINO支援將Transformer、Diffusers等常見生成式AI模型架構做轉換及最佳化,讓模型更利於在Intel平台上加速運作。
• 大型語言模型需要大規模數據訓練,訓練出來的模型體積也很龐大,需要大量的算力資源,才能訓練或快速推論一個能有效回應問題的模型。
√ OpenVINO使用模型量化壓縮技術,透過模型量化、修剪 等技術,能在可控精度的情況下,大幅減小模型體積,減少記憶體消耗及算力需求。

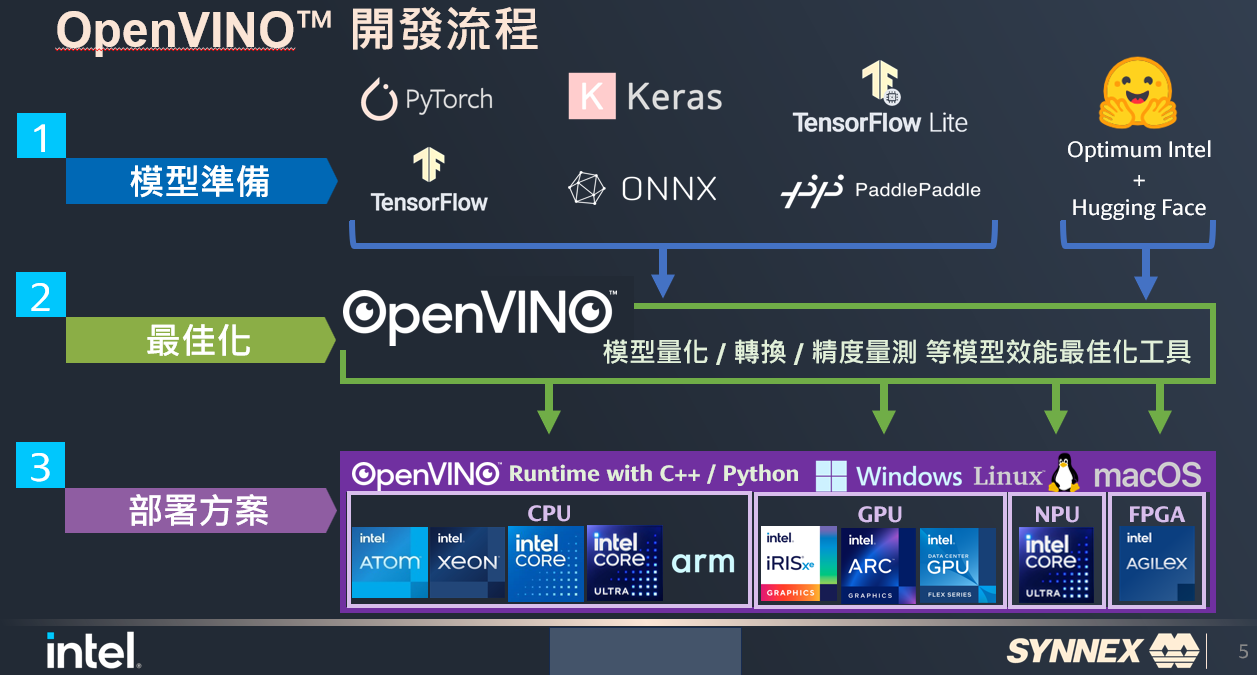
Intel OpenVINO的LLM聊天機器人,開發流程,可分三大部分:
• 模型準備階段
√ OpenVINO支援多種常見AI模型框架,包含TensorFlow跟Pytorch 。
√ 支援HugginFace開源模型庫的導入,透過Optimum Intel與Hugging Face的高度整合,可以幫助您快速利用到OpenVINO的原生API來運行推論HuggingFace上面的AI模型,發揮Intel平台的完整算力,且只需要修改2行程式碼。
• 最佳化
√ 準備好模型後再來就是要將它最佳化。 OpenVINO的模型最佳化工具Model Converter,是一個基於Python的最佳化工具,支持多種模型格式。 OpenVINO的Model Converter現在支持從PyTorch、TensorFlow、TensorFlowLite、ONNX和PaddlePaddle等多種格式轉換模型到OpenVINO的中間表示 (IR) 格式。
√ Model Converter運用了各種技術與演算法,來最佳化原來神經網路的模型推論效能,並可以減少模型大小。
√ 允許在資源有限的環境中有效率的轉換大型模型,並顯著提高了性能。
√ 能夠針對各種Intel硬體的特性,去幫模型最佳化,讓模型能在Intel硬體上取得最佳效能。
• 部屬方案
√ 用一套Runtime API,就能運作在Intel各個平台的CPU、內顯GPU、Intel的外插顯卡Arc、最新一代Intel Core Ultra平台的NPU上面,可以輕鬆指派模型要跑在哪個平台,甚至能協調把推論任務分給哪些運算裝置上。
OpenVINO在這三大部分中,都包含了非常豐富的
• 開源的範例深度學習模型
• 豐富支援的深度學習框架
• 多種易於使用的效能最佳化及分析工具
• 方便使用的通用API介面
• 多種部署方式,支援部署在多種平台
Intel同時也在OpenVINO Notebooks中提供了許多可以運行的Jupyter notebooks。 這些Jupyter notebooks是由Intel精心設計,目的是要為開發者提供一個實用的學習平台,讓大家能夠快速掌握OpenVINO的核心概念和技術。
這些notebooks包含了豐富的範例和教程,從基礎知識到進階技巧,涵蓋了深度學習推理的各個方面。 無論您是AI領域的新手還是經驗豐富的專家,都能在這裡找到適合自己的學習資源,並且能輕鬆的運作範例,包含LLM聊天機器人。
更重要的是,這些notebooks教會開發者如何有效利用Intel的API來最佳化他們的深度學習模型。 透過實際操作,您將學會如何將模型從原始框架轉換為OpenVINO的中間表示 (IR) 格式,並在Intel硬件上實現高效的推理。
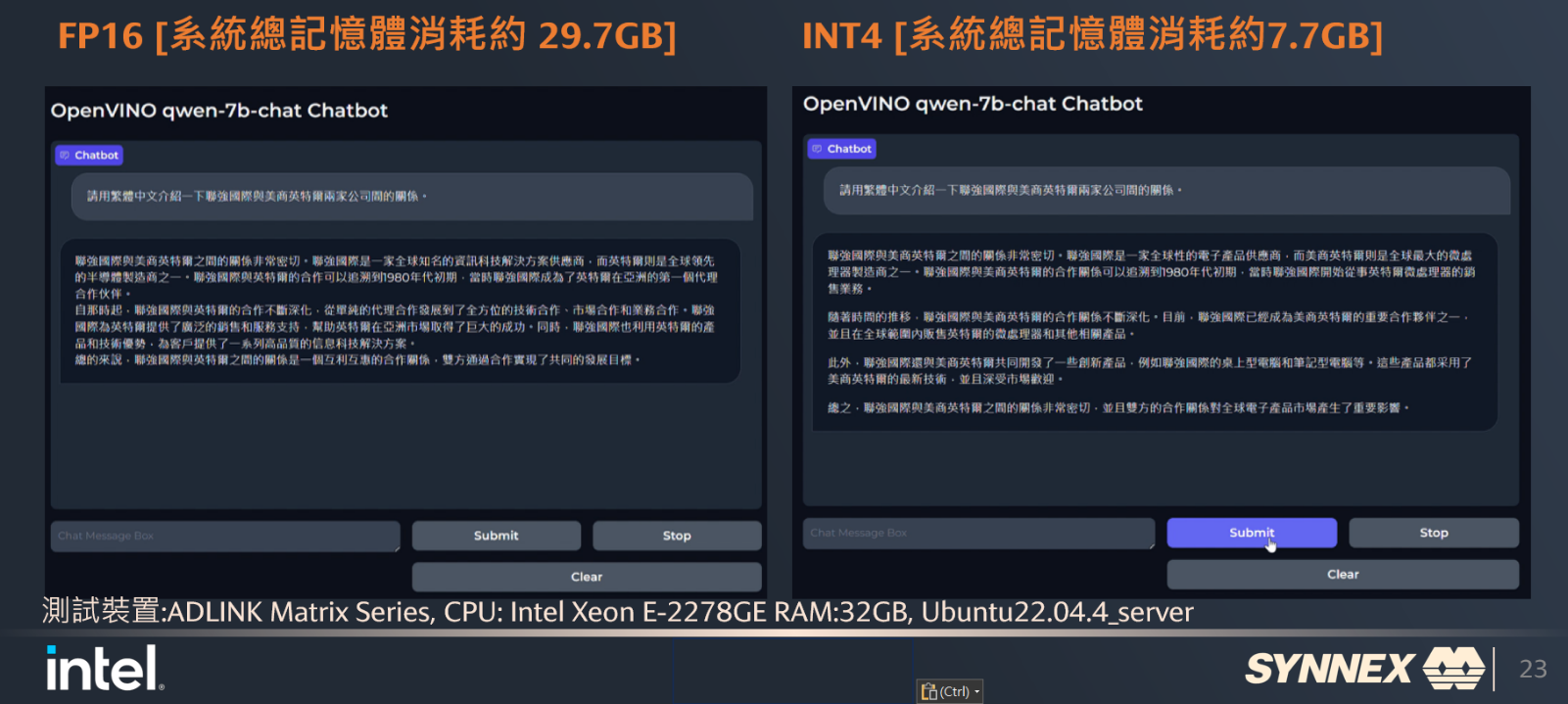
聯強國際也透由Intel提供的工具與範例,將LLM聊天機器人,運行在2019年推出的XEON-E2278GE這款8核16執行緒處理器,加上32GB RAM的平台。
詢問了通義千問7B的模型〝關於聯強國際與Intel的關係〞,INT4的場景下,44秒就完成了完整的回應。 而FP16的情況則需花費約180秒。 可以看到它的回應無論是在FP16還是INT4,內容都大致是合理的,沒有偏離事實太遠,但是回應的速度卻大有不同,所占用的記憶體也差非常多。 由此可以驗證模型量化對於導入AI有多重要,再次驗證了OpenVINO工具能簡單輕鬆的大幅提升整體AI效能。
OpenVINO Notebooks還有很多其他方面的生成式AI範例。 例如在文字生成圖片、影像轉換為文字描述、文字生成影片、文字生成聲音等等,都可以利用OpenVINO Notebooks來讓手上的Intel PC激發它在生成式AI上面的巨大潛能。
* 想要更詳細了解快速地在Intel平台上建置LLM聊天機器人的步驟及流程,歡迎與我們聯繫: mstech@synnex.com.tw

